Dynamically Reading Data from Graph APIs
Sometimes due to the following reasons, you might not want to create a concrete type to use as the target type for the deserialization of an API call result:
- In some graph APIs, for instance, Facebook graph API, There are too many return types, and creating a concrete class for each of them might not be a good idea.
- The structure of the API result is not similar to the entities of your domain model, and you cannot map the two in one simple mapping. For example, your interpretation of the address concept might differ from that of the writers of the API. In this case, in addition to mapping, some conversion is necessary.
- You are not sure of the exact return type of the API result to deserialize the result to a suitable concrete type. You might want to dynamically check, for example, a JSON field in the API result, and if the result was your desired one, you then convert it to a concrete type. For example, different error messages contain different fields for expressing the reason for API call errors.
- Although the general API return type is fixed, one or more fields might be available or not based on the access type or other criteria. For example, in the pagination example, if the number of results exceeds the specified page size, you might see fields for navigating to the next or previous pages. Conversely, if the resulting number is less than the page size, you might not see any fields for navigation.
- You want to access the inner fields of API results without deserializing the whole object tree to a concrete type. For example, the result of an API call might be a complex object with a network of nested objects. If you want to pick only some fields from the innermost objects, deserializing the whole object might not be a good decision.
In the mentioned situation, you can dynamically read data from the API result without mapping the result to a concrete type. My utility has three simple methods:
TryExtractValue:
It tries to extract value from the defined path. In the case of successful value extraction, the result of the operation will be true, and the extracted value will return to the caller. If it cannot find the path or encounters any problems during the operation, the result of the operation will be false, and the default value of the defined return type will return to the caller.
ExtractValue:
It tries to extract value from the defined path. In the case of successful value extraction, the extracted value will return to the caller. If it cannot find the path or encounters any problems during the operation, an exception will be thrown.
HasValue
It tries to figure out whether a value exists in the defined path. If the value exists in the defined path, the result of the operation will be true. If it encounters any problems during the operation or there is no value, the result of the operation will be false.
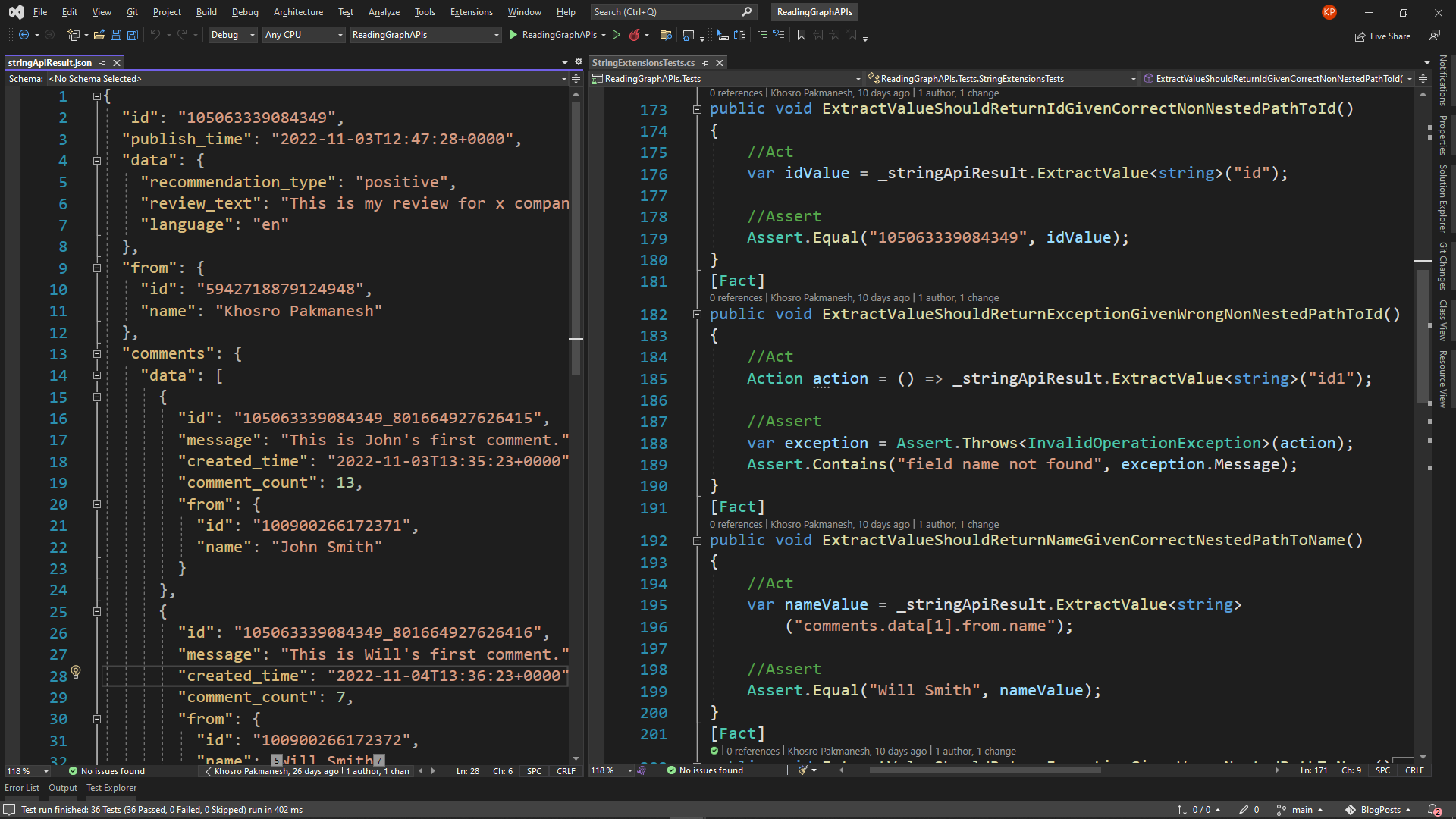
Consider the following JSON data from the Facebook graph API. After the caller sends a requests to the Facebook graph API to get reviews of a Facebook page, she receives the following result. A single review along with its comment has the following structure. I omitted some fields for the sake of simplicity.
{
"id": "105063339084349",
"publish_time": "2022-11-03T12:47:28+0000",
"data": {
"recommendation_type": "positive",
"review_text": "This is my review for x company.",
"language": "en"
},
"from": {
"id": "5942718879124948",
"name": "Khosro Pakmanesh"
},
"comments": {
"data": [
{
"id": "105063339084349_801664927626415",
"message": "This is John's first comment.",
"created_time": "2022-11-03T13:35:23+0000",
"comment_count": 13,
"from": {
"id": "100900266172371",
"name": "John Smith"
}
},
{
"id": "105063339084349_801664927626416",
"message": "This is Will's first comment.",
"created_time": "2022-11-04T13:36:23+0000",
"comment_count": 7,
"from": {
"id": "100900266172372",
"name": "Will Smith"
}
}
],
"paging": {
"cursors": {
"before": "QVFIUkQ3Y0VuS0IzZAXdZAbV81NDI0M001ZAWlGWlM1TUFHV1JDVVdPR25ldjl5dUZAuN1NFdnR0X21TSFduMUxoRmU1Sm5Ma2ZAYM3NScl9KMU56RTRCWEpmWmtR",
"after": "QVFIUlRWTDYzUWpQZAWtTN0JYTGhSakxfVEVuZA0R3d2VYMDBwQXBXUHIzWjRYNGx1OWE1aXhNaDJVV0R3WG1JcDVfc1EtdlNEZAXc1VEkta01WbVhfWDJFV3lB"
}
}
}
}
I make some examples to demonstrate the application of the utility class. Note that here the variable _stringApiResult, which you can see in the unit tests, is JSON string result of an API call.
var operationResult = _stringApiResult.TryExtractValue
("id", out string idValue);
//Output:
//operationResult => true
//idValue => 105063339084349
var operationResult = _stringApiResult.TryExtractValue
("comments.data[1].from.name", out string nameValue);
//Output:
//operationResult => true
//nameValue => "Will Smith"
var operationResult = _stringApiResult.TryExtractValue
("data.recommendation_type", out string recommendationTypeValue);
//Output:
//operationResult => true
//recommendationTypeValue => "positive"
var operationResult = _stringApiResult.TryExtractValue
("comments.paging.cursors.before", out string beforeValue);
//Output:
//operationResult => true
//beforeValue => "QVFIUkQ3Y0VuS0IzZA..."
var operationResult = _stringApiResult.TryExtractValue
("comments.data[0]", out Comment comment);
//Output:
//operationResult => true
//A comment with the following properties and values:
//comment.Id => "105063339084349_801664927626415",
//comment.Message => "This is John's first comment."
//comment.CreatedTime.Date => 2022,11,3
//comment.CommentCount => 13
var operationResult = _stringApiResult.TryExtractValue
("comments.data", out List<Comment> comments);
//Output:
//operationResult => true
//A list of comments with two items
For more examples, refer to the unit tests in the source code.
Leave a Reply
Your e-mail address will not be published. Required fields are marked *